Шифр виженера
Содержание:
Как создать сложный пароль?
Создать пароль с маленькими и большими буквами можно вручную (вот подробная инструкция) либо при использовании специализированных на этом программ — генераторов сложных паролей. При самостоятельном создании сложного пароля можно, например, использовать такой простой способ:
- Напечатайте несколько английских или русских слов, переключив клавиатуру в английскую раскладку. Для примера это будут слова — «eto moy parol».
- Некоторые из букв переведите в верхний регистр, чтобы получилось что-то вроде — «eTO moY PaRol».
- Теперь вместо пробелов (можно еще и в начале или в конце), вставьте цифры, а лучше двух или трехзначные числа (можно дату какую-нибудь вставить) — «eTO18moY12PaRol1989».
- Если система, в которой осуществляется регистрация, позволяет использовать спецсимволы, не будет лишним использовать и их — «%eTO18$moY12$PaRol1989%».
В нашем случае получился довольно длинный пароль, состоящий из 23 знаков. Если система не позволяет использовать такие длинные парольные фразы, просто удалите некоторые символы.
Гораздо проще создавать надежные пароли, используя для этого генераторы — утилиты для компьютера или скрипты, размещаемые на различных сайтах. Также можно использовать систему хранения паролей MultiPassword, в которую встроен генератор надежных паролей.
В качестве другого примера рассмотрим сервис AZPassword, который предлагает сразу три способа создания сложных паролей:
1. Генерация пароля (или одновременно нескольких — вплоть до 50 штук) по параметрам. Просто задаем желаемую длину (до 30 знаков), затем указываем программе, какие символы использовать в пароле — цифры, спецсимволы, русские/английские буквы в верхнем/нижнем регистре:

2. Создание пароля на основе введенной фразы, закодированной посредством алгоритма шифрования Base64. Довольно интересная функция. Нам нужно ввести в соответствующее поле программы любую фразу (можно даже любые символы, доступные на клавиатуре), после чего утилита, используя алгоритм Base64, сгенерирует надежный пароль.

3. Создание пароля путем кодирования введенной фразы алгоритмом ROT47. Функция, аналогичная предыдущей, но в результате шифрования в парольной фразе будут присутствовать спецсимволы.

Заметим, что шифрование одной и то же фразы алгоритмами Base64 и ROT47 всегда приводит к одному и тому же результату, независимо от того, выполняется ли кодирование в программе AZPassword или где-либо еще (например, на каком-нибудь сайте). Эта особенность метода позволяет быстро генерировать пароль непосредственно перед его вводом в форму авторизации на сайте, в компьютерной системе и т.д. Достаточно лишь точно вписать фразу (последовательность символов), на основе которой был изначально сгенерирован пароль.
Для надежного хранения паролей рекомендуем использовать систему MultiPassword:
- Современные технологии защиты (AES-256, RSA, PBKDF2, HKDF).
- Оконечное шифрование данных.
- Двойная защита паролей и другие технологии защиты паролей.
По сравнению с кодами
В нетехническом использовании «(секретный) код » обычно означает «шифр». Однако в рамках технических обсуждений слова «код» и «шифр» относятся к двум различным концепциям. Коды работают на уровне смысла, то есть слова или фразы преобразуются во что-то еще, и такое разбиение на части обычно сокращает сообщение.
Примером этого является код коммерческого телеграфа, который использовался для сокращения длинных телеграфных сообщений, возникших в результате заключения коммерческих контрактов с использованием обмена телеграммами .
Другой пример — шифры целого слова, которые позволяют пользователю заменять целое слово символом или символом, во многом подобно тому, как японцы используют символы кандзи (японские) для дополнения своего языка. ex «Быстрая коричневая лиса перепрыгивает через ленивую собаку» превращается в «Быстрая коричневая прыгает 上 ленивая».
Шифры же работают на более низком уровне: на уровне отдельных букв, небольших групп букв или, в современных схемах, отдельных битов и блоков битов. В некоторых системах в одной системе использовались как коды, так и шифры, а для повышения безопасности применялось супер-шифрование . В некоторых случаях термины коды и шифры также используются как синонимы подстановки и транспозиции.
Исторически криптография была разделена на дихотомию кодов и шифров; а у кодирования была своя собственная терминология, аналогичная терминологии шифров: « кодирование , кодовый текст , декодирование » и так далее.
Однако коды имеют множество недостатков, включая уязвимость к криптоанализу и сложность управления громоздкой кодовой книгой . Из-за этого коды вышли из употребления в современной криптографии, а шифры являются доминирующей техникой.
Почему шифрование слабое?
Как бы ни был прост в понимании и применении шифр Цезаря, он облегчает любому взлом дешифровки без особых усилий.
Шифр Цезаря – это метод подстановочного шифрования, при котором мы заменяем каждый символ в тексте некоторым фиксированным символом.
Если кто-то обнаружит регулярность и закономерность появления определенных символов в шифротексте, он быстро определит, что для шифрования текста был использован шифр Цезаря.
Если убедиться, что для шифрования текста использовалась техника шифра Цезаря, то восстановить оригинальный текст без ключа будет проще простого.
Простой алгоритм Brute Force вычисляет оригинальный текст за ограниченное время.
Атака методом перебора
Взлом шифротекста с помощью шифра Цезаря – это просто перебор всех возможных ключей.
Это осуществимо, потому что может существовать только ограниченное количество ключей, способных генерировать уникальный шифротекст.
Например, если в шифротексте зашифрованы все строчные буквы, то все, что нам нужно сделать, это запустить шаг расшифровки со значениями ключа от 0 до 25.
Даже если бы пользователь предоставил ключ выше 25, он выдал бы шифротекст, равный одному из шифротекстов, сгенерированных с ключами от 0 до 25.
Давайте рассмотрим шифротекст, в котором зашифрованы все строчные символы, и посмотрим, сможем ли мы извлечь из него разумный шифротекст с помощью атаки “методом перебора”.
У нас есть текст:
Сначала определим функцию расшифровки, которая принимает шифротекст и ключ и расшифровывает все его строчные буквы.
Теперь у нас есть наш текст, но мы не знаем ключа, т.е. значения смещения. Давайте напишем атаку методом перебора, которая пробует все ключи от 0 до 25 и выводит каждую из расшифрованных строк:
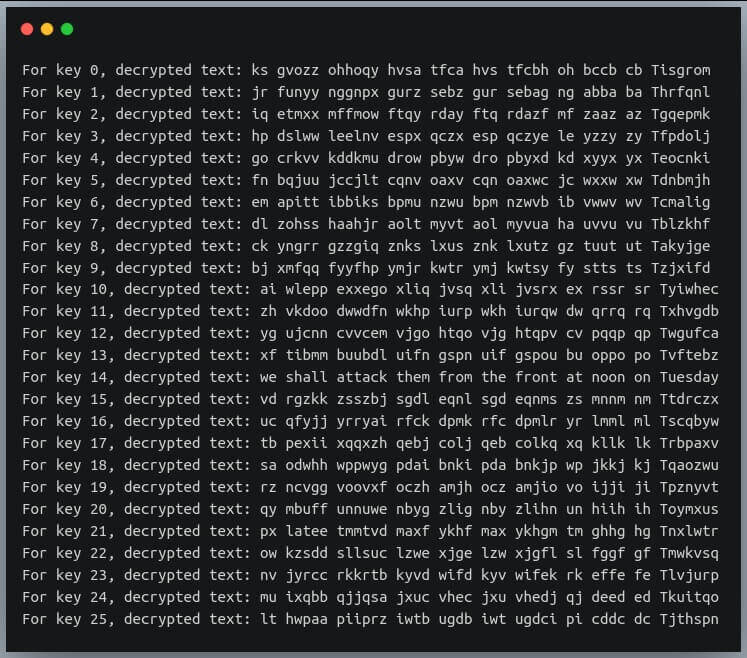
В выводе перечислены все строки, которые могут быть получены в результате расшифровки.
Если вы внимательно посмотрите, строка с ключом 14 является правильным английским высказыванием и поэтому является правильным выбором.

Теперь вы знаете, как взломать шифр с помощью шифра Цезаря.
Мы могли бы использовать другие более сильные варианты шифра Цезаря, например, с использованием нескольких сдвигов (шифр Виженера), но даже в этих случаях определенные злоумышленники могут легко расшифровать правильную расшифровку.
Поэтому алгоритм шифрования Цезаря относительно слабее современных алгоритмов шифрования.
Шифр Вернама — это сложно
Теперь попробуем объяснить подробнее.
1. Сообщение хранится в виде битов данных. Допустим, мы шифруем текст. Компьютер не умеет работать с текстом как таковым, он этот текст хранит как набор числовых кодов (проще говоря, у компьютера все буквы пронумерованы и он помнит только эти номера).
Числа, в свою очередь, компьютер хранит в виде двоичного кода, то есть битов данных. Это пока что не относится к шифрованию, это просто то, как хранится любая текстовая информация в компьютере.
| Буква | Код в ASCII | Биты данных |
| K | 75 | 01001011 |
| O | 79 | 01001111 |
| D | 68 | 01000100 |
Если мы напишем KOD в кодировке ASCII, то для компьютера это будет последовательность из трёх чисел, а каждое число — это набор битов:
01001011 01001111 01000100
2. Берём случайные биты в качестве ключа шифрования. На входе у нас три числа по 8 бит. Чтобы их зашифровать, нам нужны 24 случайных бита. Возьмём их с потолка, они ничего не значат:
10101101 01111010 10101011
3. Накладываем коды друг на друга и применяем алгоритм шифрования. Шифр Вернама построен на принципе «исключающего ИЛИ», он же XOR. Он смотрит на каждую пару битов и пытается понять, они одинаковые или разные. Если биты одинаковые, результат проверки будет 0, если разные — 1.
Можно проверить себя так: XOR задаёт вопрос «Эти биты разные»? Если да — то 1, если нет — то 0.
| Буква K | 1 | 1 | 1 | 1 | |
| Ключ | 1 | 1 | 1 | 1 | 1 |
| XOR (Они разные?) | 1 | 1 | 1 | 1 | 1 |
Если мы таким образом закодируем три буквы, мы получим три новых набора битов:
| KOD (сообщение) | 01001011 | 01001111 | 01000100 |
| Ключ | 10101101 | 01111010 | 10101011 |
| Результат шифрования с помощью XOR | 11100110 | 00110101 | 11101111 |
Получается, что на входе у нас было 24 бита данных и на выходе 24 бита данных. Но эти данные теперь совсем другие. Если перевести эти числа обратно в текст, мы получим:
KOD → æ5ï
Алгоритм шифрования ADFGX
Это самый известный шифр Первой мировой войны, используемый немцами. Свое имя шифр получил потому, что алгоритм шифрования приводил все шифрограммы к чередованию этих букв. Выбор самих же букв был определен их удобством при передаче по телеграфным линиям. Каждая буква в шифре представляется двумя. Рассмотрим более интересную версию квадрата ADFGX, которая включает цифры и называется ADFGVX.
| A | D | F | G | V | X | |
| A | J | Q | A | 5 | H | D |
| D | 2 | E | R | V | 9 | Z |
| F | 8 | Y | I | N | K | V |
| G | U | P | B | F | 6 | O |
| V | 4 | G | X | S | 3 | T |
| X | W | L | Q | 7 | C |
Алгоритм составления квадрата ADFGX следующий:
- Берем случайные n букв для обозначения столбцов и строк.
- Строим матрицу N x N.
- Вписываем в матрицу алфавит, цифры, знаки, случайным образом разбросанные по ячейкам.
Составим аналогичный квадрат для русского языка. Например, создадим квадрат АБВГД:
| А | Б | В | Г | Д | |
| А | Е/Е | Н | Ь/Ъ | А | И/Й |
| Б | Ч | В/Ф | Г/К | З | Д |
| В | Ш/Щ | Б | Л | Х | Я |
| Г | Р | М | О | Ю | П |
| Д | Ж | Т | Ц | Ы | У |
Данная матрица выглядит странно, так как ряд ячеек содержит по две буквы. Это допустимо, смысл послания при этом не теряется. Его легко можно восстановить. Зашифруем фразу «Компактный шифр» при помощи данной таблицы:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
| Фраза | К | О | М | П | А | К | Т | Н | Ы | Й | Ш | И | Ф | Р |
| Шифр | бв | гв | гб | гд | аг | бв | дб | аб | дг | ад | ва | ад | бб | га |
Таким образом, итоговое зашифрованное послание выглядит так: «бвгвгбгдагбвдбабдгвдваадббга». Разумеется, немцы проводили подобную строку еще через несколько шифров. И в итоге получалось очень устойчивое к взлому шифрованное послание.
использованная литература
- Ричард Дж. Олдрич, GCHQ: История самого секретного разведывательного управления Великобритании без цензуры , HarperCollins, июль 2010 г.
- Хелен Фуше Гейнс, «Криптоанализ», 1939, Дувр. ISBN 0-486-20097-3
- Ибрагим А. Аль-Кади , «Истоки криптологии : вклад арабов», Cryptologia , 16 (2) (апрель 1992 г.), стр. 97–126.
- Дэвид Кан , Взломщики кодов — История секретного письма ( ISBN 0-684-83130-9 ) (1967)
- Дэвид А. Кинг , Шифры монахов — забытая числовая система средневековья , Штутгарт: Франц Штайнер, 2001 ( ISBN 3-515-07640-9 )
- Абрахам Синьков , Элементарный криптоанализ: математический подход , Математическая ассоциация Америки, 1966. ISBN 0-88385-622-0
- Уильям Столлингс , Криптография и сетевая безопасность, принципы и практика, 4-е издание
- Стинсон, Дуглас Р. (1995), Криптогафия / Теория и практика , CRC Press, ISBN 0-8493-8521-0
Множественные смещения (шифрование по Виженеру)
До сих пор мы использовали одно значение сдвига (ключ) для сдвига всех символов в строках на одинаковое количество позиций.
Мы также можем попробовать вариант, в котором мы будем использовать не одну клавишу, а последовательность клавиш для выполнения различных сдвигов в разных позициях текста.
Например, допустим, мы используем последовательность из 4 клавиш: 1,5,2,3] При таком методе наш первый символ в тексте сдвинется на одну позицию, второй – на пять позиций,
третий символ на две позиции, четвертый на три позиции, а затем снова пятый символ будет сдвинут на одну позицию, и так далее.
Это улучшенная версия шифра Цезаря, которая называется шифром Виженера.
Давайте применим шифр Виженера на практике.
Функция выполняет как шифрование, так и дешифрование, в зависимости от значения булевого параметра “decrypt”.
Мы отслеживаем общее количество зашифрованных/расшифрованных строчных букв с помощью переменной i, используем ее с оператором modulus, чтобы определить, какой ключ из списка использовать следующим.
Обратите внимание, что мы сделали операцию сдвига очень компактной; это эквивалентно многоэтапному процессу преобразования между Unicode и символьными значениями и вычисления сдвига, который мы видели ранее. Давайте попробуем использовать эту функцию на примере другого простого текста:
Давайте попробуем использовать эту функцию на примере другого простого текста:
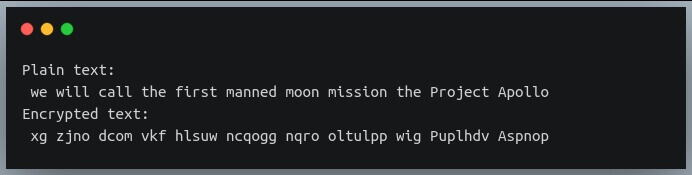
Здесь мы выполняем шифрование, используя ключи , и, как и ожидалось, первый символ “w” был сдвинут на одну позицию к “x”,
второй символ “e” сдвинут на две позиции к “g”; третий символ “w” сдвинут на три позиции к “z”.
Этот процесс повторяется со следующими символами.
Выполните процесс расшифровки с теми же ключами и посмотрите, сможете ли вы снова восстановить исходное заявление.
Отрицательное смещение
До сих пор мы выполняли “положительный” или “правый” сдвиг символов в процессе шифрования. А процесс дешифровки для него же включал “отрицательный” или “левый” сдвиг символов.
Но что если мы хотим выполнить процесс шифрования с отрицательным сдвигом – изменится ли наш алгоритм шифрования-дешифрования?
Да, будет, но только немного. Единственное изменение, которое нам необходимо для сдвига влево, – это сделать знак ключа отрицательным, остальная часть процесса останется неизменной и позволит добиться результата сдвига влево в процессе шифрования и сдвига вправо в процессе расшифровки.
Давайте попробуем это сделать, изменив нашу предыдущую функцию, добавив еще один параметр – ‘shift_type’ в нашу функцию cipher_cipher_using_lookup().
Давайте попробуем этот модифицированный метод на простом тексте:

Обратите внимание, что каждый из символов нашего обычного текста сдвинут на три позиции влево. Теперь проверим процесс расшифровки с помощью той же строки
Теперь проверим процесс расшифровки с помощью той же строки.

Таким образом, мы можем зашифровать и расшифровать текст, используя таблицу поиска и отрицательный ключ.
Шифрование цифр и знаков препинания
Теперь, когда мы увидели, как можно кодировать и декодировать заглавные буквы английского алфавита с помощью шифра Цезаря, возникает важный вопрос – а как насчет других символов?
Как насчет цифр, как насчет специальных символов и знаков препинания?
Так, первоначальный алгоритм шифра Цезаря не должен был иметь дело ни с чем, кроме 26 букв алфавита, ни с прописными, ни со строчными.
Поэтому типичный шифр Цезаря не шифрует пунктуацию или цифры, а переводит все буквы в строчные или прописные и шифрует только эти символы.
Итак, мы попытаемся закодировать заглавные и строчные символы так, как мы это делали в предыдущем разделе, игнорируя пока пунктуацию, а затем мы также закодируем цифры в тексте.
Для чисел мы можем выполнить кодирование одним из двух способов:
- Сдвинуть значение цифр на столько же, на сколько сдвинуты буквы алфавита, то есть при сдвиге на 3 – цифра 5 становится 8, 2 – 5, 9 – 2 и так далее.
- Сделать цифры частью алфавита, т.е. за z или Z будут следовать 0,1,2. до 9, и на этот раз наш делитель для выполнения модуля будет 36, а не 26.
Мы реализуем наше решение, используя первую стратегию. Кроме того, на этот раз мы реализуем наше решение в виде функции, принимающей в качестве параметра значение смещения (которое служит ключом в Cesar Encryption).
Мы реализуем 2 функции: cipher_encrypt() и cipher_decrypt().
Создание таблицы поиска
Строковый модуль Python предоставляет простой способ не только создать таблицу поиска, но и перевести любую новую строку на основе этой таблицы.
Рассмотрим пример, когда мы хотим создать таблицу первых пяти строчных букв и их индексов в алфавите.
Затем мы используем эту таблицу для перевода строки, в которой все символы “a”, “b”, “c”, “d” и “e” заменены на “0”, “1”, “2”, “3” и “4” соответственно, а остальные символы не тронуты.
Для создания таблицы мы будем использовать функцию maketrans() модуля str.
Этот метод принимает в качестве первого параметра строку символов, для которых требуется перевод, и другой параметр такой же длины, содержащий сопоставленные символы для каждого символа первой строки.
Давайте создадим таблицу для простого примера.
Таблица представляет собой словарь Python, в котором в качестве ключей указаны значения символов Unicode, а в качестве значений – их соответствующие отображения.
Теперь, когда у нас есть готовая таблица, мы можем переводить строки любой длины с помощью этой таблицы.
К счастью, за перевод отвечает другая функция модуля str, называемая translate.
Давайте используем этот метод для преобразования нашего текста с помощью нашей таблицы.
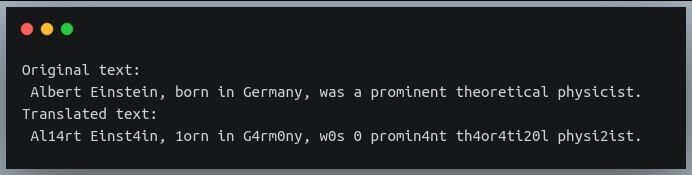
Как вы можете видеть, каждый экземпляр первых пяти строчных букв был заменен их относительными индексами.
Теперь мы используем ту же технику для создания таблицы поиска для шифра Цезаря на основе предоставленного ключа.
Типы
Существует множество различных типов шифрования. Алгоритмы, использовавшиеся ранее в истории криптографии , существенно отличаются от современных методов, и современные шифры можно классифицировать в зависимости от того, как они работают, и от того, используют ли они один или два ключа.
Исторический
Исторические ручные и бумажные шифры, использовавшиеся в прошлом, иногда называют классическими шифрами . Они включают простые шифры подстановки (например, ROT13 ) и шифры транспонирования (например, шифр Rail Fence ). Например, «ХОРОШАЯ СОБАКА» может быть зашифрована как «PLLX XLP», где «L» заменяет «O», «P» — «G» и «X» вместо «D» в сообщении. Перестановка букв «ХОРОШАЯ СОБАКА» может привести к «ДГОГДОО». Эти простые шифры и примеры легко взломать даже без пар открытый текст-зашифрованный текст.
Простые шифры были заменены полиалфавитными шифрами подстановки (такими как шифры Виженера ), которые изменили алфавит подстановки для каждой буквы. Например, «GOOD DOG» может быть зашифрован как «PLSX TWF», где «L», «S» и «W» заменяют «O». Даже при небольшом количестве известного или предполагаемого открытого текста простые полиалфавитные шифры замещения и шифры перестановки букв, разработанные для шифрования пером и бумагой, легко взломать. Тем не менее, можно создать надежную ручку и бумажный шифр на основе одноразового блокнота , но при этом одноразовых блокнотов .
В начале двадцатого века были изобретены электромеханические машины для шифрования и дешифрования с использованием транспозиции, полиалфавитной замены и своего рода «аддитивной» замены. В роторных машинах несколько дисков ротора обеспечивали полиалфавитную замену, а вставные платы обеспечивали другую замену. Ключи легко менялись, меняя диски ротора и провода коммутационной панели. Хотя эти методы шифрования были более сложными, чем предыдущие схемы и требовали машин для шифрования и дешифрования, для взлома этих методов были изобретены другие машины, такие как British Bombe .
Современный
Современные методы шифрования можно разделить по двум критериям: по типу используемого ключа и по типу входных данных.
По типу используемого ключа шифры делятся на:
- алгоритмы с симметричным ключом ( криптография с закрытым ключом ), где один и тот же ключ используется для шифрования и дешифрования, и
- Алгоритмы с асимметричным ключом ( криптография с открытым ключом ), где для шифрования и дешифрования используются два разных ключа.
В алгоритме с симметричным ключом (например, DES и AES ) отправитель и получатель должны иметь общий ключ, настроенный заранее и хранящийся в секрете от всех других сторон; отправитель использует этот ключ для шифрования, а получатель использует тот же ключ для дешифрования. Шифр Фейстеля использует комбинацию замещения и транспозицию методов. Большинство алгоритмов блочного шифрования основано на этой структуре. В алгоритме с асимметричным ключом (например, RSA ) есть два отдельных ключа: открытый ключ публикуется и позволяет любому отправителю выполнять шифрование, в то время как закрытый ключ хранится получателем в секрете и позволяет только этому человеку выполнить правильное дешифрование.
Шифры можно разделить на два типа по типу входных данных:
- блочные шифры , которые шифруют блок данных фиксированного размера, и
- потоковые шифры , которые шифруют непрерывные потоки данных.
Цифровые шифры
В отличие от шифровки текста алфавитом и символами, здесь используются цифры. Рассказываем о способах и о том, как расшифровать цифровой код.
Двоичный код
Текстовые данные вполне можно хранить и передавать в двоичном коде. В этом случае по таблице символов (чаще всего ASCII) каждое простое число из предыдущего шага сопоставляется с буквой: 01100001 = 97 = «a», 01100010 = 98 = «b», etc
При этом важно соблюдение регистра
Расшифруйте следующее сообщение, в котором использована кириллица:
Шифр A1Z26
Это простая подстановка, где каждая буква заменена её порядковым номером в алфавите. Только нижний регистр.
Попробуйте определить, что здесь написано:
Шифрование публичным ключом
Алгоритм шифрования, применяющийся сегодня буквально во всех компьютерных системах. Есть два ключа: открытый и секретный. Открытый ключ — это большое число, имеющее только два делителя, помимо единицы и самого себя. Эти два делителя являются секретным ключом, и при перемножении дают публичный ключ. Например, публичный ключ — это 1961, а секретный — 37 и 53.
Открытый ключ используется, чтобы зашифровать сообщение, а секретный — чтобы расшифровать.
Как-то RSA выделила 1000 $ в качестве приза тому, кто найдет два пятидесятизначных делителя числа:
Внедрение шифрования
Давайте создадим функцию caesar_cipher(), которая принимает строку для шифрования/дешифрования, “набор символов”, показывающий, какие символы в строке должны быть зашифрованы (по умолчанию это будет строчный регистр),
ключ, а также булево значение, показывающее, была ли произведена расшифровка (шифрование) или нет.
Это очень мощная функция!
Вся операция смены была сведена к операции нарезки.
Кроме того, мы используем атрибут string.ascii_lowercase – это строка символов от “a” до “z”.
Еще одна важная особенность, которой мы здесь достигли, заключается в том, что одна и та же функция обеспечивает как шифрование, так и дешифрование; это можно сделать, изменив значение параметра ‘key’.
Операция вырезания вместе с этим новым ключом гарантирует, что набор символов был сдвинут влево – то, что мы делаем при расшифровке сдвинутого вправо шифротекста Цезаря.
Давайте проверим, работает ли это на предыдущем примере.
Мы зашифруем только заглавные буквы текста и передадим то же самое параметру “characters”.
Зашифруем текст: “HELLO WORLD! Welcome to the world of Cryptography!”.

Посмотрите, как часть “KHOOR ZRUOG” соответствует шифрованию “HELLO WORLD” с ключом 3 в нашем первом примере.
Также обратите внимание, что мы указываем набор символов для заглавных букв с помощью string.ascii_uppercase. Мы можем проверить, правильно ли работает расшифровка, используя тот же зашифрованный текст, который мы получили в нашем предыдущем результате
Мы можем проверить, правильно ли работает расшифровка, используя тот же зашифрованный текст, который мы получили в нашем предыдущем результате.
Если мы можем получить наш исходный текст, значит, наша функция работает идеально.

Обратите внимание, как мы установили параметр “decrypt” нашей функции в True. Поскольку мы восстановили наш оригинальный текст, это признак того, что наш алгоритм шифрования-дешифрования с использованием таблицы поиска работает отлично!
Поскольку мы восстановили наш оригинальный текст, это признак того, что наш алгоритм шифрования-дешифрования с использованием таблицы поиска работает отлично!
Теперь давайте посмотрим, можно ли расширить набор символов, включив в него не только строчные и прописные символы, но и цифры и знаки препинания.
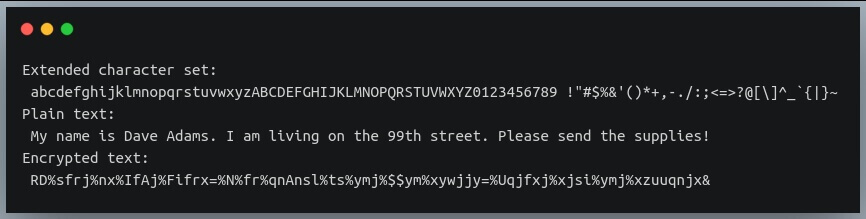
Здесь мы включаем все символы, которые мы обсуждали до сих пор (включая символ пробела), в набор символов для кодирования.
В результате все (даже пробелы) в нашем обычном тексте было заменено другим символом!
Единственное отличие заключается в том, что обертывание происходит не по отдельности для строчных и прописных символов, а в целом для набора символов.
Это означает, что “Y” со смещением 3 не станет “B”, а будет закодирован как “1”.
Шифр Виженера
Данный шифр на порядок более устойчив к взлому, чем моноалфавитные, хотя представляет собой шифр простой замены текста. Однако благодаря устойчивому алгоритму долгое время считался невозможным для взлома. Первые его упоминания относятся к 16-му веку. Виженер (французский дипломат) ошибочно считается его изобретателем. Чтобы лучше разобраться, о чем идет речь, рассмотрим таблицу Виженера (квадрат Виженера, tabula recta) для русского языка.

Приступим к шифрованию фразы «Касперович смеется». Но, чтобы шифрование удалось, нужно ключевое слово — пусть им будет «пароль». Теперь начнем шифрование. Для этого запишем ключ столько раз, чтобы количество букв из него соответствовало количеству букв в шифруемой фразе, путем повтора ключа или обрезания:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | |
| Фраза: | К | А | С | П | Е | Р | О | В | И | Ч | С | М | Е | Е | Т | С | Я |
| Ключ | П | А | Р | О | Л | Ь | П | А | Р | О | Л | Ь | П | А | Р | О | Л |
Теперь по таблице Виженера, как по координатной плоскости, ищем ячейку, которая является пересечением пар букв, и получаем: К + П = Ъ, А + А = Б, С + Р = В и т. д.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | |
| Шифр: | Ъ | Б | В | Ю | С | Н | Ю | Г | Щ | Ж | Э | Й | Х | Ж | Г | А | Л |
Получаем, что «касперович смеется» = «ъбвюснюгщж эйхжгал».
Взломать шифр Виженера так сложно, потому что для работы частотного анализа необходимо знать длину ключевого слова. Поэтому взлом заключается в том, чтобы наугад бросать длину ключевого слова и пытаться взломать засекреченное послание.
Следует также упомянуть, что помимо абсолютно случайного ключа может быть использована совершенно разная таблица Виженера. В данном случае квадрат Виженера состоит из построчно записанного русского алфавита со смещением на единицу. Что отсылает нас к шифру ROT1. И точно так же, как и в шифре Цезаря, смещение может быть любым. Более того, порядок букв не должен быть алфавитным. В данном случае сама таблица может быть ключом, не зная которую невозможно будет прочесть сообщение, даже зная ключ.